Second attempt at Kaggle's Titanic data set, accuracy up to 78%, notes on preprocessing and Pandas
Getting up to 78% on the Titanic dataset
My goal today was to get at or above 77% in Kaggle's Titanic: Learning from Disaster starter competition after getting 73% on my first attempt. and I managed to do so, though not in the way I expected.
I spent most of the time exploring the dataset to decide whether two of the features I dropped from the dataset could be of use and concluded that they could:
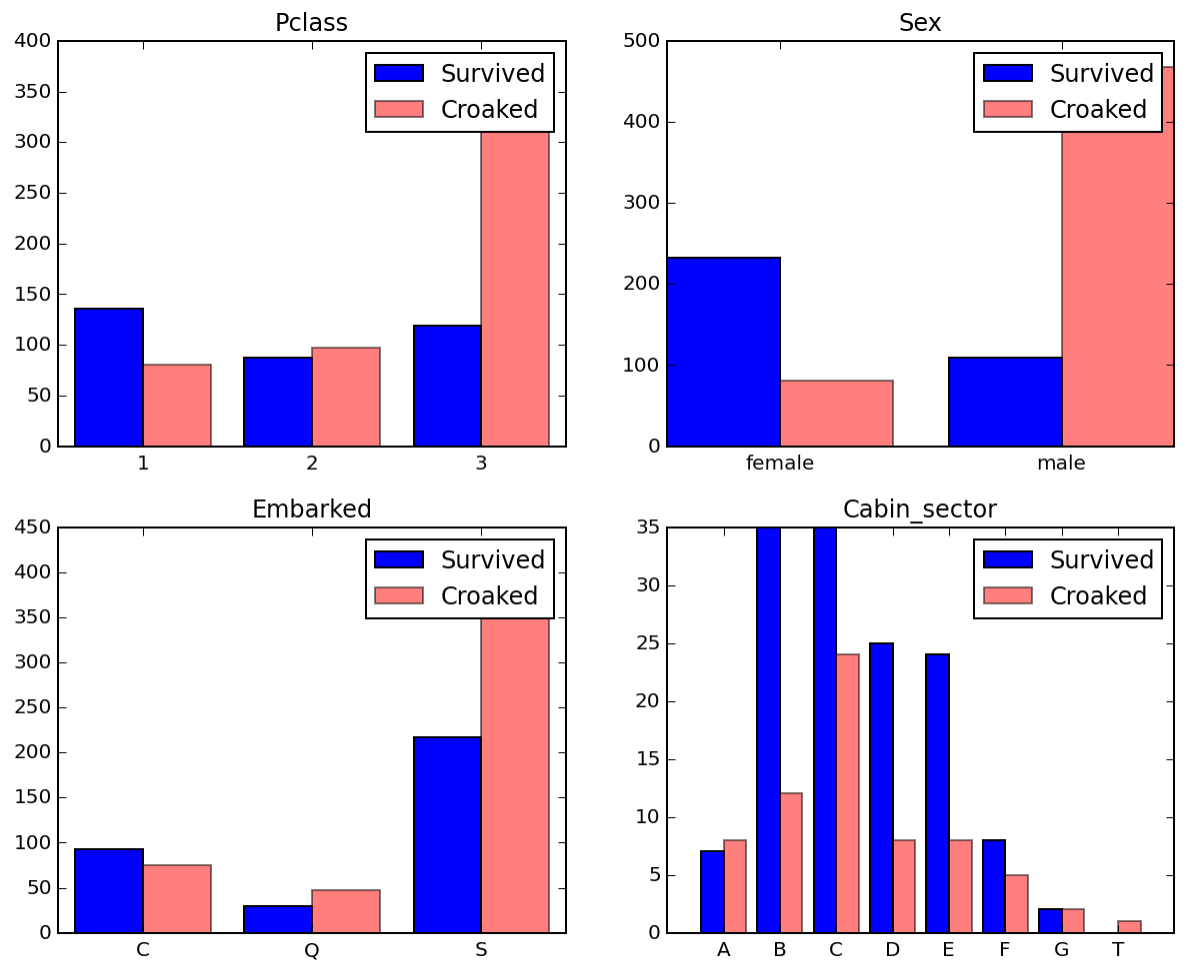
It appears that those who depart from Southampton croak disproportionately and that those who stayed in cabin sectors b, c, d and e survived disproportionately. Note that I did a little bit of feature engineering by segmenting the raw cabin into a sector by taking the first letter.
Indeed, adding these features boosted logistic regression by a couple points (from 73% to 75%), but it wasn't until I simply tried submitting a solution predicted by a decision tree model that I reached my goal—and it turns out doing so with my original simplified dataset worked just as well!
So my intuition that futzing with more models was less important that looking more deeply at the features was not quite right. I think the answer is that both are important, and it always helps to get some intuition by exploring the data.
Preprocessing data
The two things I spent the most time on during these attempts was preprocessing the data and figuring out how to get matplotlib to do what I wanted.
For preprocessing features, here is the approach:
- Binary Categorical variables should be mapped to 0, 1 if they haven't already
- Ordinal categorical variables should be mapped to real numbers, e.g 1, 2, 3, ... up to the N possible values the variable takes
- Categorical variables with more than one value need to be one-hot encoded, that is, flattened out into one binary variables per possible value. So variable 'color' with values 'blue', 'green', 'red' gets mapped to 'is_green', 'is_blue', 'is_red'. Any missing values can simply have 0s across the board
- Missing values for quantitative variables can be filled in with the median or mean. So if we don't know how old someone is, we assume he/she is the average age.
- All quantitative features are scaled to center at mean 0 with standard deviation 1 so that the values take the form of a normal distribution
- All categorical features (now mapped to binary) are pushed to -1 or 1
An important point emphasized by the Python ML book:
Again, it is also important to highlight that we fit the StandardScaler only once on the training data and use those parameters to transform the test set or any new data point.
The preprocessing higher order function I wrote takes this into account by capturing a StandardScaler fit to the training set that is used by the preprocessing function it returns, which can then be reused to preprocess other datasets.
See the notebooks for all the details.
Pandas
Pandas is quite helpful for most data processing needs mentioned above. I'm finding it's worth taking time to understand the two key data structures provided: Series and DataFrames. The book Python for Data Analysis by the author of Pandas and is worth picking up too.
Pandas suffers from a bit of a kitchen sink OO API for my taste compared to the elegance of, say, Clojure's Seq library or Ruby's Enumerable, but I'm overall grateful they exist and have come to prefer working with them over using numpy 2d arrays directly.
Kaggle
I'm loving Kaggle. Having real datasets to work with and a sense via the leaderboards as to whether you are doing a competitive job is great, and the forums have plenty of tips if you are looking for hints. One key decision they made product wise that I appreciate is to allow you to submit and receive a score for competitions after they have closed so every competition can continue to serve as a training ground, so perhaps more important that recognizing ML skills, they are building up a database of challenges / tutorials.
The Python Machine Learning book is the perfect way to get ramped up to feeling comfortable attempting competitions. If you are in a rush, reading chapters 1, 3 and 4 should be plenty to get you going.