A conference-like day: high level understanding of MCMC and connecting with a study buddy
Today I didn't really get anything done, but had fun exploring some high level ideas and got to geek out about ML for a couple of hours. It was a lot like attending a conference!
High level reading / listening about Bayesian methods
Talking Machines
First, I carefully re-listened to the first 5 minutes or so of episode 10 of The Talking Machines podcast for another excellent overview of a concept from Ryan Adams, this time on Markov Chain Monte Carlo a.k.a MCMC. What was most interesting to me was where MCMC fits within Bayesian Inference:
- In Bayesian models, we write down some joint distribution between stuff we can see in the world (the data we can observe) and some properties of the data that we want to understand. We can use conditional probability to reason about the things we can’t see given the things we can see. Ideally we could marginalize away maybe things we can’t see but that we don’t care about. This comes up e.g with LDA maybe we don’t care about what particular topic is assigned to one word in a document—we’re more interested in what’s going on in the corpus in general, integrating out the specific assignments.
- Marginalization is something that we do a lot of, but unfortunately it involves summing out some big state space, or integrating over a big state space. Integration is something that is something that is hard to do.
- Aside: we can divide a lot of the computations we do in ML and stats into two categories:
- finding the best configuration that we frame in terms of optimization
- integrating out different possible configurations looking at many different hypothesis, and that’s what marginalization or integration is about
- There are many approaches to marginalization.
- Sometimes, in a few models, it turns out that you can do marginalization exactly using something like dynamic programming. You can propagate information on a graph and perform a hard sum or a hard integral
- More often, you have complicated data and you have to do something fancier. This field is known as approximate inference. Quite a few different ways to think about this. Two dominating approaches:
- Variational inference: try to come up with an approximating distribution
- Markov Chain Monte Carlo
Ok so that frames MCMC within Bayesian inference as one of the main techniques for marginalization.
So what is MCMC:
- What we’re trying to do is ask questions about the data, and we can often write these questions as expectations under distributions. The idea of Monte Carlo is that we can use samples from a distribution, compute their averages and those give us estimates of these expectations we want to compute. Many questions we ask about data can be framed in these terms.
- The problem is that, in addition to integration being hard, drawing samples from distributions is hard.
- The idea of Markov Chain Monte Carlo is that we can define a random walk where the steps in the random walk are simple and have a small set of rules, such that we can write an algorithm to simulate the random walk. As we run this random walk forward, it will converge to a sample from this very complicated distribution.
- MCMC dates back to last century, a big advance came with the Metropolis Hastings algorithm which was developed surrounding the Manhattan Project
- MCMC is the gold standard for performing statistical inference in some of the hardest problems in stats, ML and physics. It can be challenging and slow to perform, still an active area of research.
This is close to a transcript from the episode, worth a quick listen if you'd like to hear it from Ryan himself.
The Master Algorithm
I remembered that The Master Algorithm also talked about MCMC towards the end of its chapter on Bayesian methods, so I went back and re-read that next. It has a nice build up from bayes theorem to naive bayes classification to markov chains to bayesian networks to markov networks.
PyData talk
Next I remember that I had this video from the PyData conference on my YouTube watch later list:
I watched it and it got be excited about some of the bayesian statistical libraries like PyMC3.
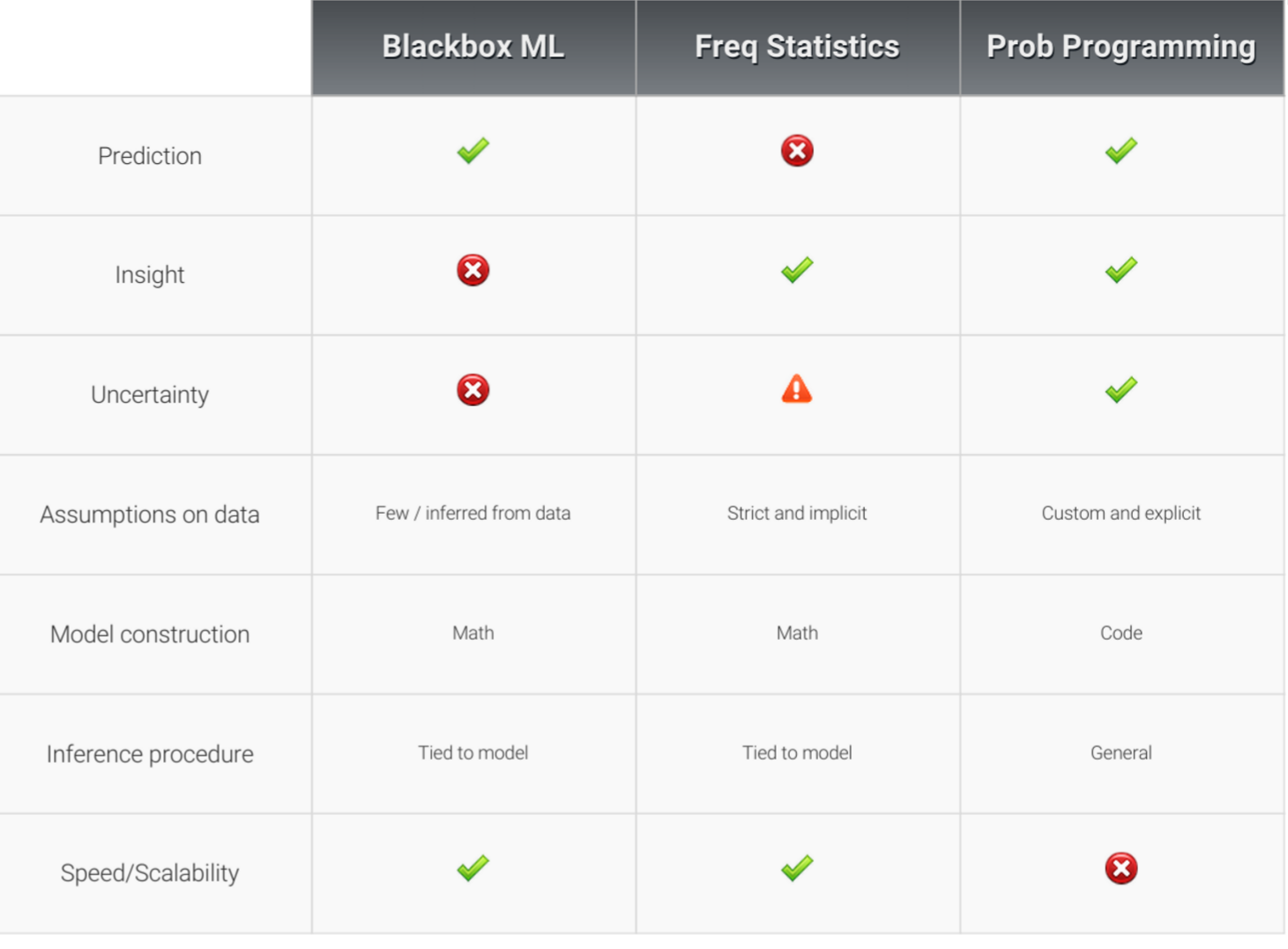
Overall I think Bayesian / graphical models are exciting because they have the promise of providing insight in the model itself along with the predictive power you'd get with something like a neural network:
The talk also listed what seem like great resources, and I've added them to the curriculum page: Doing Bayesian Data Analysis and examples ported to Python and PyMC3 and iPython notebook.
I think following up working through a book like that could be a nice follow up to the Python Machine Learning book. But the trick is to not have so many days like today that I don't even get finished with that :)
An ML Study Buddy
A fun outcome of the HN Coverage of my sigmoid notebook is that a fellow aspiring ML expert, VJ, reached out to me, and we'd scheduled a skype call for today. We ended up comparing notes and experiences in our efforts to craft a good curriculum and geeking out about all things ML and programming for a while. One frustration we share is in finding material that does a good job of both providing rigor and giving enough background to help gain intuition behind the concepts. E.g pages of formal definitions or "for dummy" watered down analogies, but the key seems to be to connect the two together.
We plan to keep in touch and work through some of the Python ML book together and attack a Kaggle data set as well. VJ seems to have a stonger stats background and has offered to help me get over any probability theory humps which is great.