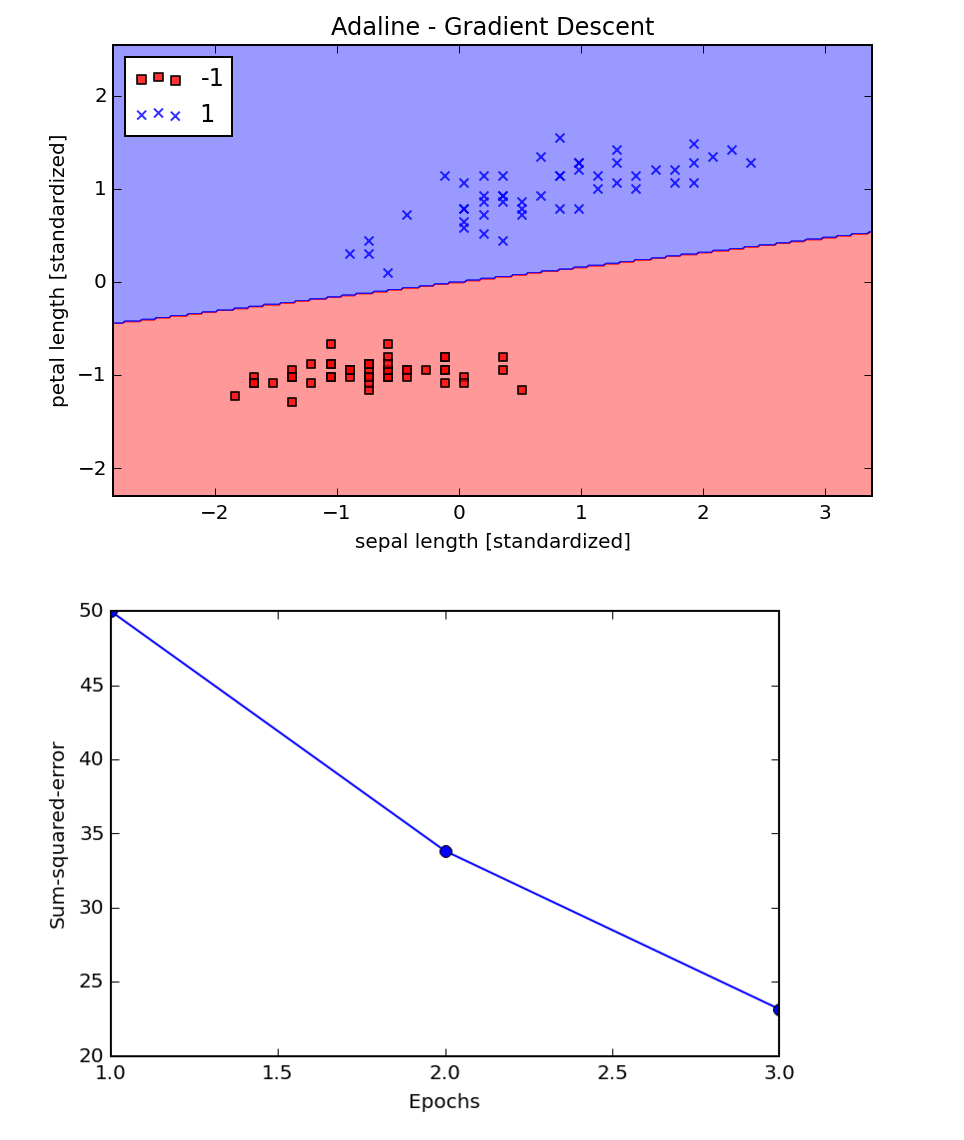
Feature scaling to improve performance of gradient descent.
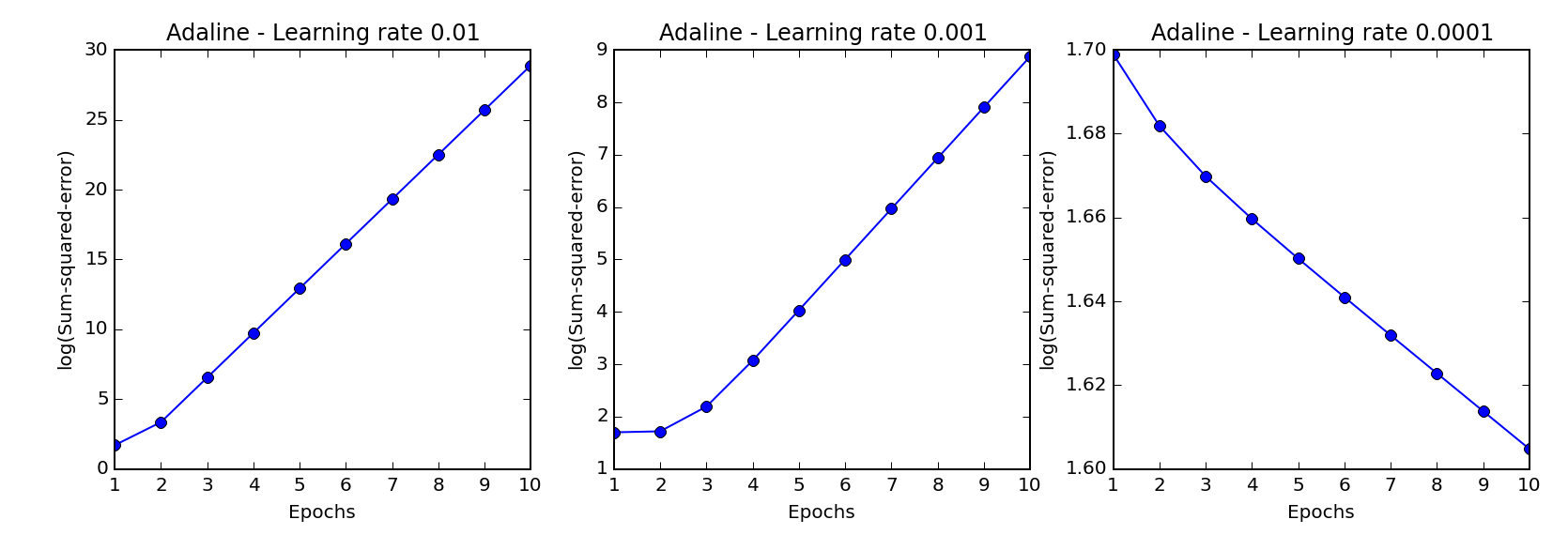
Continuing on in chapter 2, we drill a little deeper into how the learning rate affects convergence. My chapter 2 notebook has been updated to show this analysis, but what's cool is that after finding that it takes a really small learning rate of 0.001 to converge, you can regularlize the training samples (a form of feature scaling) and then converge much faster with a learning rate of 0.01: