Python ML book ch2 and improving on the perceptron using gradient descent.
Back at chapter 2 of Python Machine Learning: after implementing the basic perceptron algorithm there's a follow up to implement a slightly more sophisticated single neuron model: ADAptive LInear NEuron (Adaline).
With the original perceptron training function (here's my implementation, we determine how far we are off by subtracting the correct output with the predicted output after we've already gone through the activation function that pushes the value to 1 or -1, and the fact that the activation function does the quantizing means we've lost some resolution about how far we are off. This is where Adaline improves:
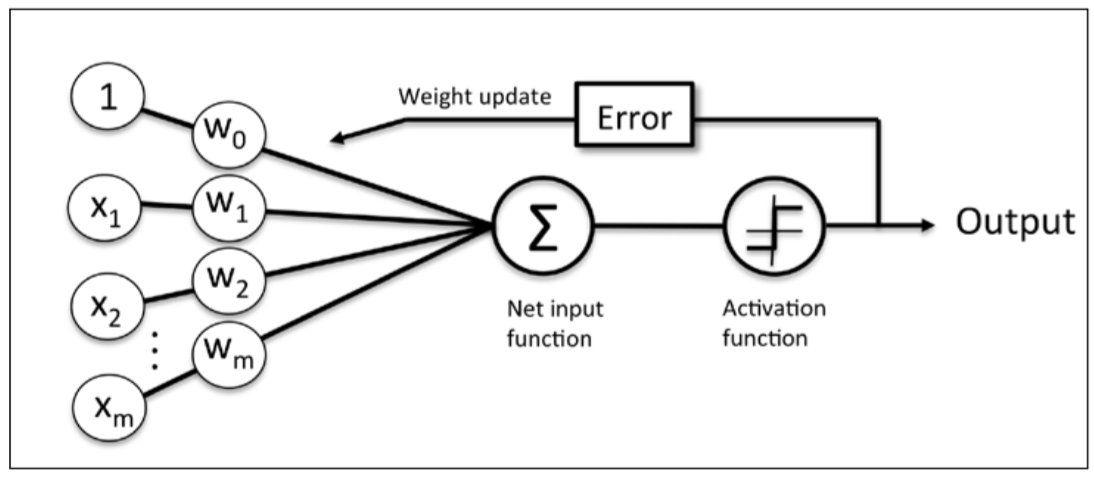
vs
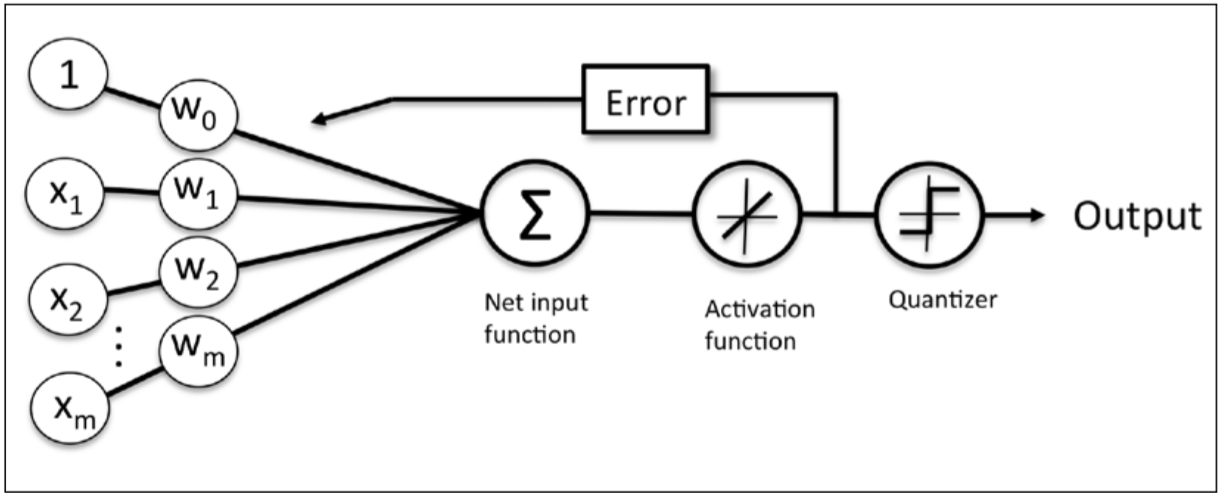
as the author puts it, "If we compare the preceding figure to the illustration of the perceptron algorithm that we saw earlier, the difference is that we know to use the continuous valued output from the linear activation function to compute the model error and update the weights, rather than the binary class labels."
The other difference in the adeline training procedure is it bases the weight delta based on the errors of every training observation at once instead of updating the weights one at a time. Again, the author, "the weight update is calculated based on all samples in the training set (instead of updating the weights incrementally after each sample), which is why this approach is also referred to as "batch" gradient descent."
Finally, the book goes into detail of framing the problem as minimizing a cost function. You start with some random weights (or all zeros) and see how far you are off on all of the training samples. Once you form a cost function to quantify how far you are off, you can think about updating a weights in order to minimize this cost:
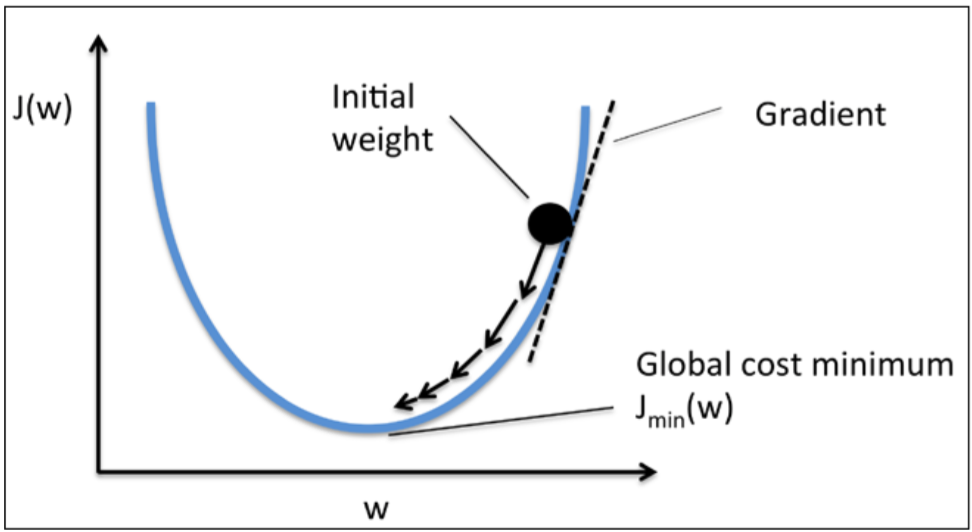
so each step is taking a little step down the curve, e.g "gradient descent". For this implementation I didn't look at the author's solution until I could figure it out myself, and also took the time to calculate the derivative of the cost function myself on paper, which dusted off the old chain rule from calculus.
In implementing / figuring out how to implement adeline, I got stuck for a while in figuring out how to vectorize the batch update calculation. All in all it was a good 2 hours of putzing around debugging the function until I got this one line figured out:
weight_deltas = learning_rate * np.dot(observations.transpose(), errors)
but I'm glad I went through this pain as I understand it much better than had I simply refactored a working solution as I did the first time. I also got stuck because I started out with too high of a training rate, so I thought there was a bug, but it turns out I was just bouncing around the cost function:
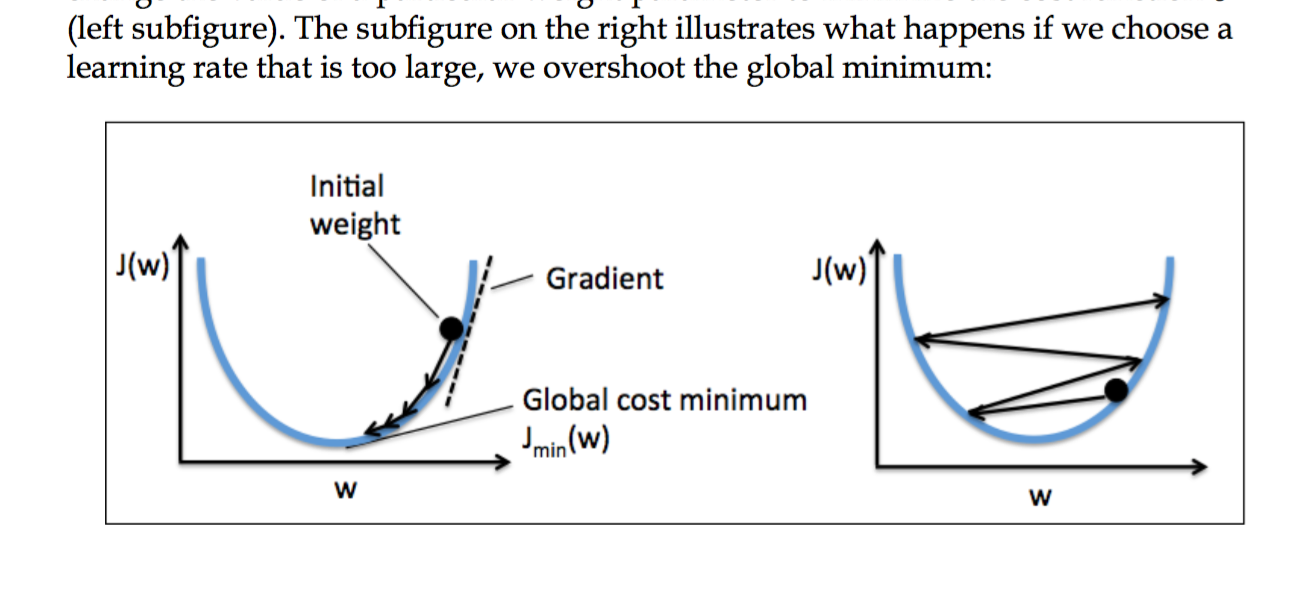
just as the book described a page later :)