Statistical sampling, Designing studies
Sampling
Resuming where I left off in the stanford online class, Producing Data: Sampling.
Sampling methods:
- simple random sampling: randomly choose N from population (equivalent to picking name out of a hat)
- cluster sampling: given a population divided into many groups, randomly choose N groups and use all members for your population
- stratified sampling: given a population divided into groups, randomly choose a subset within each group
- systematic sampling: choose at a regular interval, e.g every 50th person, or first person to walk in room each hour
- multi-stage sampling: first choose random cluster, then randomly choose within each (stratified limited to subset of clusters). could be more complicated chains of stages going between simple, cluster and stratified.
Crappy sampling methods:
- volunteer sample: ask a population to fill out a survey, only those who agree are included
- convenience sample: ask the next 5 people who walk by
Determining whether a sample is biased
- If an attribute of a population is known to follow a normal distribution, comparing the mean of the sample vs entire population is sufficient. Example from course: the SAT scores of a student population.
- Otherwise, it's best to compare the measures of range (min, max, quartiles and medians)
Designing Studies
Skills:
- Determine whether a study is observational (prospective or retrospective), or an experiment
- Critique a sample survey for flaws in questions
- Determine whether an experiment is blind or double blind (or neither)
A study examines the relationship between two variables. The difference between an observational study and an experimental study is whether or not their is intervention to control the values of the explanatory variable in the study or whether the population reports or is observed to have particular values for the explanatory variable. For instance, the explanatory variable could be weight loss technique and the response variable would be whether an individual loses 5 lbs over 2 months. In both cases, you would perhaps conduct a survey to attempt to select a representative sample of the adult population who are attempting to lose weight. In an observational study, you would ask what technique they are using to try and lose weight (e.g diet, exercise, diet & exercise) and in an experiment you would assign the participants to one of the techniques.
Observational studies
If a correlation is established in an observational study, can causation be inferred? Not really, due to what was covered earlier with the idea of a lurking variable. For instance, say the approach 'diet & exercise' is highly correlated with success in losing weight, but it turns out that is also very highly correlated with gender, the lurking variable that could just as well explain the likelihood of succeeding in losing weight.
Controlling for (lurking) variables
All is not lost: even in an observational study, you can try to account, or control for any variable you think could be lurking by making sure you have that captured about each participant. In the weight loss example, if you had captured gender, you could see that it is correlated with the choice of diet.
It's impossible to control for all variables and it may be hard to capture some potential lurking variables, such as "desire to lose weight". All that said, as the course states,
If great care is taken to control for the most likely lurking variables (and to avoid other pitfalls which we will discuss presently), and if common sense indicates that there is good reason for one variable to cause changes in the other, then researchers may assert that an observational study provides good evidence of causation.
Other difficulties:
- asking to report on behavior changes the prospective behavior (e.g someone reporting on TV watching and snacking might cut back while logging it day to day)
- a retrospective study can avoid this, but then you have the possibility of people failing to remember details accurately
Sample Surveys
Pitfalls of surveys:
- open questions: indeterminate number of possible answers, harder to reason about, e.g "what is your favorite food?"
- closed questions without thorough options and escape valve, e.g "favorite music: rock and roll or ska?"
- leading questions: the question shouldn't make clear what the survey hopes the answer would be
- unbalanced questions: scale doesn't have equal number of positive / negative e.g 'disagree, agree, strongly agree'
- sensitive questions: reason to believe respondent will not answer accurately, e.g "do you do drugs?"
Experiments
In an experiment the explanatory variable, aka 'factor' is assigned by the experimenter to participants to one of the possible values, aka 'treatments', thus dividing the sample into 'treatment groups'.
When the population is randomly assigned, you have a randomized controlled trial. This is considered the best way to determine causation because by randomly assigning, you've reduced the chances that another lurking variable is correlated with the assignment
... the groups should not differ significantly with respect to any potential lurking variable. Then, if we see a relationship between the explanatory and response variables, we have evidence that it is a causal one.
Another way of putting it: you've automatically controlled for all lurking variables.
Note: the word 'control' is used in many senses w.r.t experiment design:
- In an observational study, you can 'control' for potentially lurking variables aka confounding factors by measuring them along with the explanatory variable
- Experiments are 'controlled' in that the experimenter controls how the population is assigned to treatments
- A control group is a treatment group given no intervention
Important ways of improving random experiment design:
- the participants don't know which group they are in to control for the placebo affect
- the experimenters who are assessing outcomes don't know the assignment to avoid their bias in recording results
when both of these are in place, a study is 'double blind'.
Even moar pitfalls:
- The experimental condition is not realistic; the phenomenon whereby people in an experiment behave differently from how they would normally behave is called the Hawthorne effect.
- Noncompliance: participants don't do as they are assigned (e.g diet only when assigned diet & exercise)
- Unethical to assign potentially harmful behavior, e.g randomly assign half population to take crack everyday to see if it affects wellbeing
- Impossible to assign some values, e.g gender, age
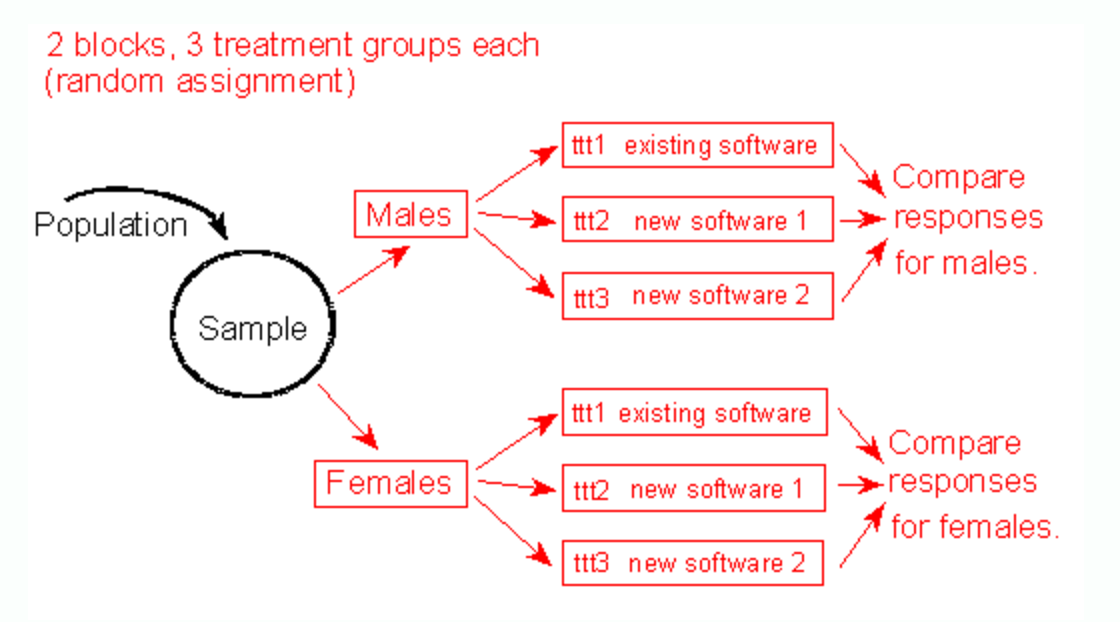
Randomization tweaks
If you have two variables you are looking at, you need a population for each combination of values. If you have a smaller population and are already dividing into several groups, the odds of getting individuals with another potentially lurking variable lumped together (e.g all males) due to chance is higher.
In these cases, if you'd particularly like to control for a particular variable, you can first divide the population by on variable, then randomly assign to treatment groups.