K-nearest neighbors, getting started with ch04 (data preprocessing) and Kaggle's Titanic data set
K-nearest neighbors algorithm
Wrapped up chapter 3 of Python Machine learning by applying the K-nearest neighbor algorithm.
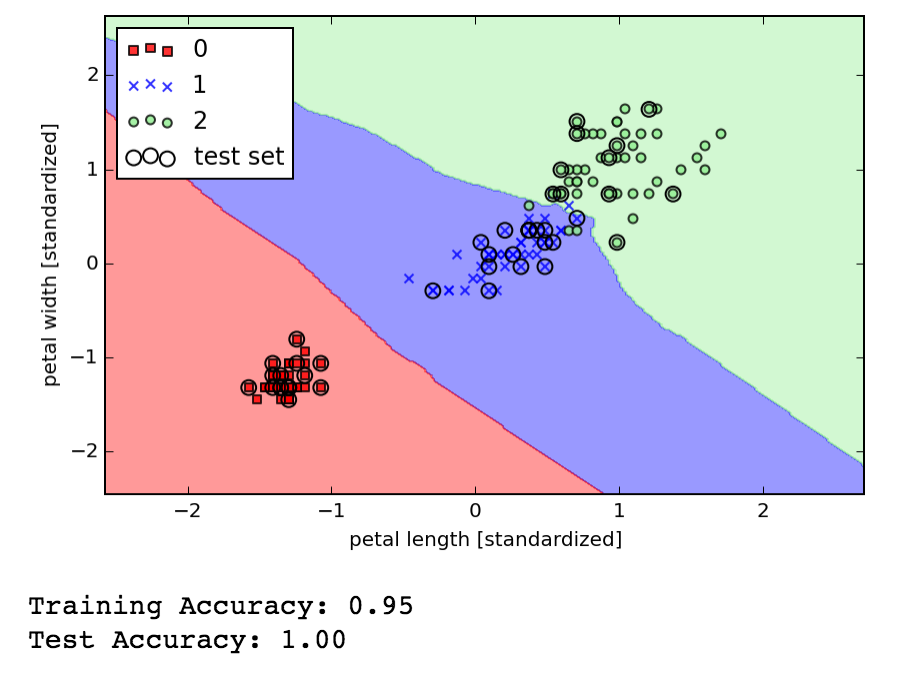
KNN is clever, it just indexes the training data so that predicting a new value is finding the k closest data points and using them to vote on the class membership. It can learn on the fly as new known data points can be added to the training set at any time. The disadvantage is the space needed to keep the model on hand, and that the live lookup cost is proportional to the size of the training set (either linear or logarithmic depending on how the storage / indexing is optimized). It also apparently performs poorly in high dimensional space where being "close" becomes less meaningful and where sparseness can also mean there isn't really anything close to a new data point we wish to classify. However, we'll learn in the coming chapters about dimensionality reduction.
Data preprocessing
Got started on chapter 4 which is all about data preprocessing. There are some standard techniques for dealing with missing data, including filtering out, and filling in values with something sensible like the mean (e.g for any missing 'height' value just fill in the average height). My WIP.
My first Kaggle
Per recommendations I chose this starter kaggle competition that asks you to build a model to predict survivorship as my first Kaggle competition. I feel like I've learned just enough scikit-learn to tackle this so I don't want to delay any further, even if the data preprocessing know-how is arriving just in time. I just got far enough to load in the data and sketch out a preprocessing strategy. My WIP.