Santosh Venkatesh's Theory of Probability Book, lining up more problems TODO and progress on preprocessing functionality of automatic data science tool
Another Probability Theory book
I purchased the book The Theory of Probability and recommend it as another resource (and have added it to the curriculum page accordingly). Had I found this before All of Statistics I might have chosen it as my main book, but I'm far enough along down this path, with enough of the curriculum tied to it, that I will instead stay the course and use this new book as a reference.
What's nice about the book is that it provides a bit more more motivation for having the theory of probability in the first place, and weaves together a bit more of a narrative throughout the first half as it tours many topics. The second half provides more abstract foundations that support he first half, and the preface has this crazy diagram showing how a reader can navigate the book in several different ways.
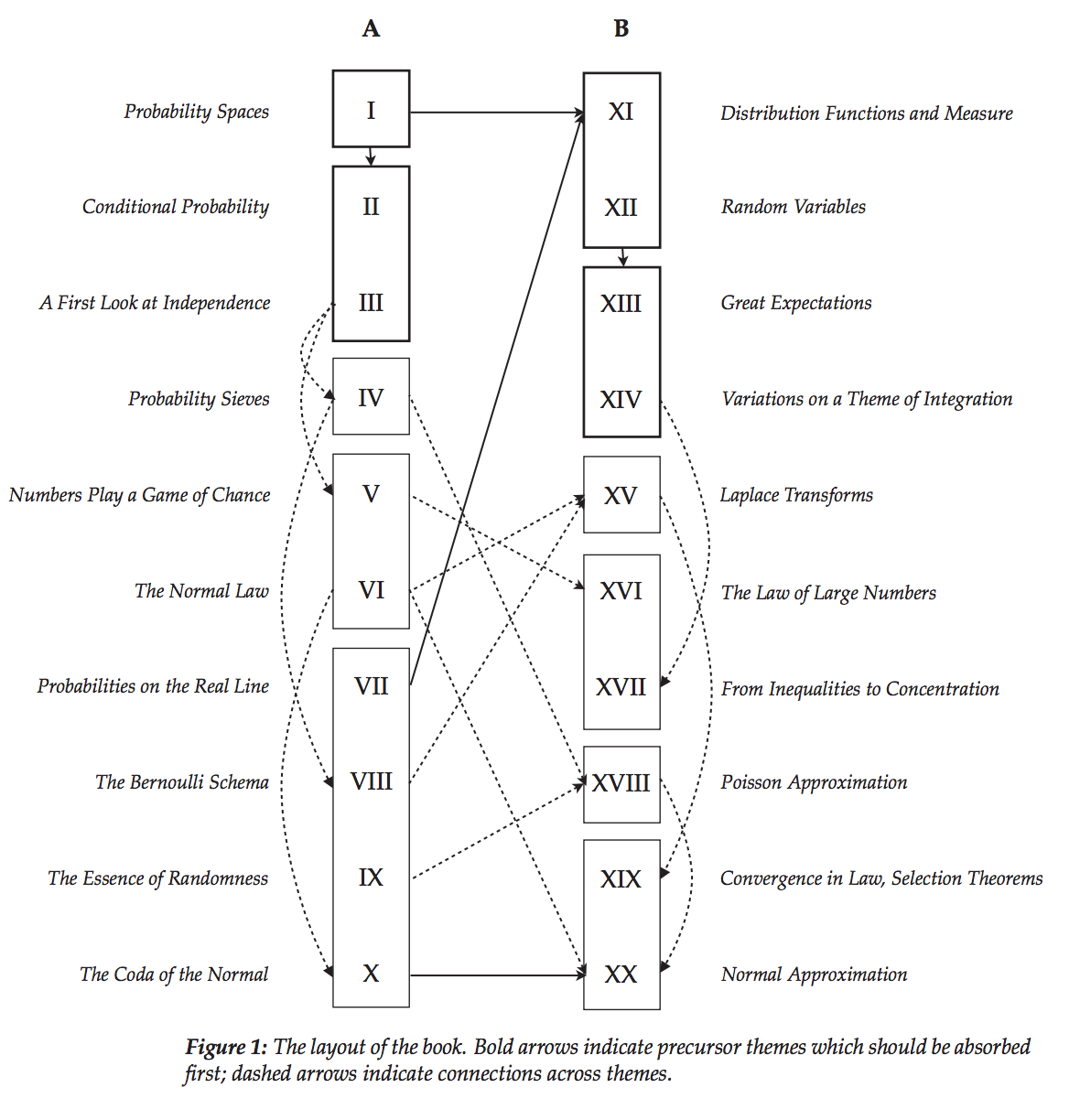
The tradeoff, of course, is that the book is over twice as long and covers fewer topics. But if I were to work through this book, I would likely need to spend less time looking for additional resources elsewhere, as I've found myself needing to do as I work through All of Statistics.
I was disappointed to find that solutions to the exercises are only provided to instructors, as it makes the book a bit less valuable for working through as a self-study, but it turns out if you view the source of the book's web page on the publisher's website you might find a naked url to the solutions manual within a JSON object encoded on the page :)
Transcribing more problems
I spent some more time transcribing problems from CMU's stats classes onto the homework section and have plenty of work cut out for me on the topics of expectation, inequalities and convergence of random variables. It's time consuming, but a nice way to line things up and prime my head for concepts ahead in the reading.
Automatic data science
I continued working on producing an idealized titanic notebook that would be generated by my tool, still getting the preprocessing steps in place.
It's looking like this so far:
preprocessor = Pipeline([
('features', FeatureUnion([
('quantitative', Pipeline([
('extract', ColumnSelector(
['Age', 'SibSp', 'Fare', 'Pclass', 'Parch'],
c_type='float'
)),
('impute-missing', Imputer(strategy='median')),
('scale', StandardScaler())
])),
('categorical', Pipeline([
('encode-categorical', EncodeCategorical()),
('combine-binary', FeatureUnion([
('onehot', Pipeline([
('select-onehot', ColumnSelector(
['Embarked']
)),
('apply-onehot', OneHotEncoder())
])),
('select-binary', ColumnSelector(
['Sex']
))
]))
]))
]))
])
along with prose describing the different preprocessing steps necessary.